Markov Decision Process(MDP : 마르코프 결정 과정)
* 마르코프 과정이란 미래의 어떤 상태가 과거의 선택뿐만 아니라 환경적 모든 것을 포함한다는 것을 의미.


s : State(현재 상태 또는 처할 수 있는 상태)
a : Action(취할 수 있는 행동)
P : 상태변환 확률
R : Reward(어떤 상태에 돌입했을때 얻는 보상)
γ 감마 : Discount(할인계수)
=> 즉, 가능한 모든 행동에 대한 최댓값
Q-Learning
* 최종적으로 도달할 수 있는 상태의 값 대신 각 행동에 해당하는 값을 보는 것.
* 행동을 정량화 할 수 있는 측정치가 필요.

R(s,a) : 보상 + 할인계수 * 도달할 상태의 기댓값(확률)
=> 앞선 마르코브에서 본 V(s) 식 중 괄호에 들어있는것과 식이 일치함
=> Q값은 행동 수행의 정량화된 계측치, V값은 결국 이러한 Q값들 중 최대치

Temporal Difference (시차)

* 사건은 무작위적으로 발생하기 때문에 Q값을 완전히 바꾸지 않고 단계적으로 조금씩 바꿔서 사용.
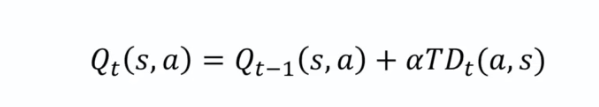

t : 시간
알파 * TD : 현재의 시간차
Deep Q-Learning
* 앞선 Q-Learning 은 굉장히 단순화된 환경에서 작동
* 어떻게 시간차 개념을 신경망에 적용 시켜 신경망의 최대 성능을 활용할 수 있나?
* 학습(Learning) : 손실값을 역전파나 확률적 경사하강법으로 네트워크를 통과시켜, 네트워크의 시냅스 가중치를 업데이트하는걸 반복.

* 행동(Action) : target 1 2 3 4 중 어떤행동을 할지 선택하는 방법으로, 고정된 Q 값을 업데이트 된 네트워크의 소프트맥스함수를 통과시켜 최적의 Q 예측값을 찾아 선택한다.
* 학습-행동 과정은 새로운 state 로 에이전트가 들어갈때마다 반복(게임 한 판이 아니라 매 상태마다 인코딩 됨을 의미.)
Experience Replay : 경험재현 (Learning 파트에서 사용)
* 에이전트가 처한 연속된 상태를 네트워크에 바로 입력하는게 아니라, 별도 에이전트 메모리에 저장해두었다가 어떤 한계점에 도달했을 때 에이전트 스스로 학습 시점을 결정 네트워크 학습을 진행하는 것을 말한다.
* 경험 배치에서 균일하게 분산된 샘플을 가져와서 학습을 진행(모든 경험을 사용X).
* 각 경험은 상황, 행동, 마지막 상태(특정 상태), 그 행동을 통해 얻은 보상 등으로 특정 지어진다.
=> 상태 1, 행동 상태 2, 보상
=> 경험들을 네트워크에 차례대로 입력하는 경우, 발생하는 경험의 연속성으로부터 오는 편향성의 패턴을 파괴할 수 있음.
=> 경험재현을 사용하는 이유.
=> 또 다른 이점으로는 경험이 배치에서 일정 시간 머무르기 때문에 에이전트가 그 경험을 통해 여러번 학습할 수 있음.
=> 또 다른 이점으로는 한번에 하나씩 배울때보다 학습 기회가 많다는 점이 있음.
Action Selection Policies : 행동 선택 정책 (Action 파트에서 사용)
* 극대점에 갇히는 행동 선택을 하지 않도록 행동 정책이 필요.
① 앱실론 그리디 : 앱실론 퍼센트만큼의 시도를 제외하고 최대 Q값을 가진 것을 선택. (ex. 앱실론을 0.5 혹은 0.05로 설정한다면 95%는 최대 Q값을 가진 행동을 취할 것이나 5%는 무작위 행동을 택함) => 앱실론의 값이 낮을수록 최적화된 행동을 위한 탐색을 더 탐욕적으로 하는 것, 탐색의 여지를 더 적게 남김.
② 앱실론 소프트 : 앱실론 그리디와 반대로 기본적으로 무작위 선택 (ex. 앱실론을 0.1 즉 10%로 설정한다면 10%만 최대 Q값을 가진 행동을 고르고 90%는 무작위 행동을 택함)
③ 소프트맥스 : 0에서 1사이 값으로 출력되고 모든 값 합이 1로 나옴. 행동이 선택되었을때의 확률값으로 사용가능.
'스터디 > AI' 카테고리의 다른 글
| [Imple] 텐서플로우 서빙(TensorFlow Serving) 분류모델 api (1) | 2023.02.13 |
|---|---|
| [Imple] Flask를 이용한 api 샘플 (0) | 2023.02.13 |
| [논문] Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition (0) | 2023.01.29 |
| [이론] 순환신경망 이론 RNN (0) | 2023.01.27 |
| [이론] 컨볼루션 신경망 이론 CNN (2) | 2023.01.27 |