이 게시물은 <만들면서 배우는 생성 AI 2판> 교재의 내용과 소스코드를 기반으로 실습한 내용을 기반으로 하고있다.
https://github.com/rickiepark/Generative_Deep_Learning_2nd_Edition/
GitHub - rickiepark/Generative_Deep_Learning_2nd_Edition: <만들면서 배우는 생성 AI 2판>의 코드 저장소
<만들면서 배우는 생성 AI 2판>의 코드 저장소. Contribute to rickiepark/Generative_Deep_Learning_2nd_Edition development by creating an account on GitHub.
github.com
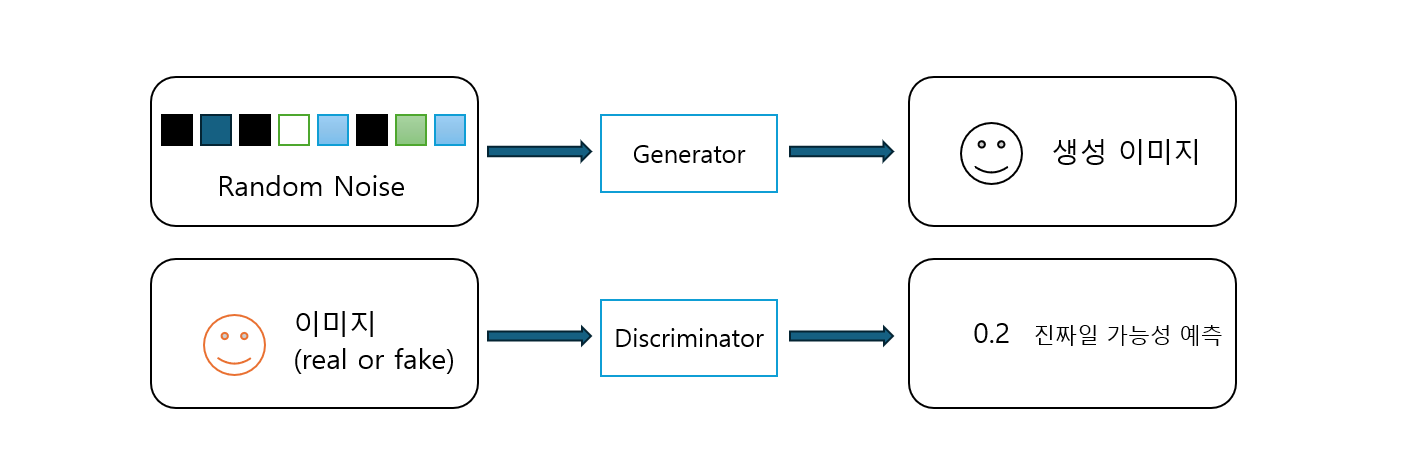
생성적 적대 신경망 (GAN)
생성적 적대 신경망 GAN은 생성자(Generator)와 판별자(Discriminator) 간 경쟁을 통해 진행되는 신경망 네트워크 시스템이다.
* 생성자 : 랜덤한 잡음을 원래 데이터셋에서 샘플링한 것처럼 보이는 샘플로 변환하는 역할
* 판별자 : 샘플이 원래 데이터셋에서 나왔는지 생성자의 위조인지 예측하는 역할
네트워크 처음 시작 시 생성자는 노이즈 이미지를 출력하고, 판별자는 무작위로 예측한다.
두 네트워크가 번갈아 훈련을 진행.
생성자가 판별자를 속이는데 익숙해지면 판별자는 이에 맞추어 어떤 샘플이 가짜인지 정확하게 식별해내야 한다.
생성자는 판별자를 속일 새로운 방법을 또 찾게 된다. => 순환 반복
심층 합성곱 GAN (DCGAN)
DCGAN은 GAN에서 직접 파생된 모델로, 생성자, 판별자에서 합성곱 신경망(convolution)과 전치 합성곱 신경망(convolution-transpose)을 사용했다는 것이 차이점이다.
실습 코드를 작성해보며 학습해보도록 한다.
데이터는 케글에서 제공하는 레고 이미지를 사용한다.
https://www.kaggle.com/datasets/joosthazelzet/lego-brick-images
Images of LEGO Bricks
40,000 images of 50 different LEGO bricks
www.kaggle.com
먼저 데이터를 불러오고, 이미지 크기를 64*64로 조정, 픽셀 사이를 보간한다.
(원본 데이터는 [0, 255] 범위로 픽셀 강도를 나타내지만 GAN 훈련 진행을 위해 데이터를 [-1, 1] 범위로 스케일 조정한다.
=> 생성자 마지막 층에서 시그모이드 함수보다 일반적으로 더 강한 그레디언트를 제공하는 탄젠트 활성화 함수를 사용하기 위함)
#사용 파라미터 정의
IMAGE_SIZE = 64
CHANNELS = 1
BATCH_SIZE = 128
Z_DIM = 100
EPOCHS = 100
LOAD_MODEL = False
ADAM_BETA_1 = 0.5
ADAM_BETA_2 = 0.999
LEARNING_RATE = 0.0002
NOISE_PARAM = 0.1train_data = utils.image_dataset_from_directory(
"./데이터경로입력",
labels=None,
color_mode="grayscale",
image_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
shuffle=True,
seed=42,
interpolation="bilinear",
)#이미지 정규화, 크기변경
def preprocess(img):
img = (tf.cast(img, "float32") - 127.5) / 127.5
return img
train = train_data.map(lambda x: preprocess(x))
다음은 GAN 에서 판별자를 구축한다.
판별자는 이미지의 진짜/가짜여부를 예측한다. (지도 학습의 이미지 분류 문제와 동일)
#판별자 구축
#판별자 Input층 (이미지) 정의
discriminator_input = layers.Input(shape=(IMAGE_SIZE, IMAGE_SIZE, CHANNELS))
#Conv2D 층을 쌓고 중간에 BatchNormal, LeakyRelu, Dropout 층 쌓음
x = layers.Conv2D(64, kernel_size=4, strides=2, padding="same", use_bias=False)(
discriminator_input
)
x = layers.LeakyReLU(0.2)(x)
x = layers.Dropout(0.3)(x)
x = layers.Conv2D(
128, kernel_size=4, strides=2, padding="same", use_bias=False
)(x)
x = layers.BatchNormalization(momentum=0.9)(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Dropout(0.3)(x)
x = layers.Conv2D(
256, kernel_size=4, strides=2, padding="same", use_bias=False
)(x)
x = layers.BatchNormalization(momentum=0.9)(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Dropout(0.3)(x)
x = layers.Conv2D(
512, kernel_size=4, strides=2, padding="same", use_bias=False
)(x)
x = layers.BatchNormalization(momentum=0.9)(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Dropout(0.3)(x)
# 마지막 Conv2D층에 시그모이드 활성화 함수를 사용해 0과 1 사이 숫자를 출력
x = layers.Conv2D(
1,
kernel_size=4,
strides=1,
padding="valid",
use_bias=False,
activation="sigmoid",
)(x)
# 마지막 합성곱 층 출력 펼침, 텐서의 크기가 1*1*1로 마지막 Dense 층 필요X
discriminator_output = layers.Flatten()(x)
# 판별자 모델 => 입력 이미지를 받아 0과 1 사이의 숫자 하나를 출력
discriminator = models.Model(discriminator_input, discriminator_output)
discriminator.summary()
Conv2D 층을 쌓을때 strides를 2로 지정해 텐서가 네트워크들을 통과하면서 공간 방향의 크기가 줄어들게 된다.
반대로 채널 수는 마지막 예측 전까지 증가하게 된다.

다음은 GAN 에서 생성자를 구축한다.
생성자의 입력은 다변량 표준 정규 분포에서 뽑은 벡터이다.
출력은 원본 훈련 데이터에 있는 이미지와 동일한 크기의 이미지이다.
=> 변이형 오토인코더(VAE)의 디코더와 정확히 동일한 목적을 수행하게 된다.
#생성자 구축
#생서자의 Input층 정의
generator_input = layers.Input(shape=(Z_DIM,))
#Reshape 층을 통해 1*1*100 크기의 텐서로 변환, 이후 전치 합성곱 층을 적용할 수 있음
x = layers.Reshape((1, 1, Z_DIM))(generator_input)
#총 네번의 전치합성곱 층 통과, 죽안에 BatchNormal, LeakyReLU 층 놓기
x = layers.Conv2DTranspose(
512, kernel_size=4, strides=1, padding="valid", use_bias=False
)(x)
x = layers.BatchNormalization(momentum=0.9)(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Conv2DTranspose(
256, kernel_size=4, strides=2, padding="same", use_bias=False
)(x)
x = layers.BatchNormalization(momentum=0.9)(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Conv2DTranspose(
128, kernel_size=4, strides=2, padding="same", use_bias=False
)(x)
x = layers.BatchNormalization(momentum=0.9)(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Conv2DTranspose(
64, kernel_size=4, strides=2, padding="same", use_bias=False
)(x)
x = layers.BatchNormalization(momentum=0.9)(x)
x = layers.LeakyReLU(0.2)(x)
#마지막 전치합성곱 층은 탄젠트 활성화 함수를 사용해 출력을 원본 이미지 도메인과 같은 [-1, 1] 범위로 변환
generator_output = layers.Conv2DTranspose(
CHANNELS,
kernel_size=4,
strides=2,
padding="same",
use_bias=False,
activation="tanh",
)(x)
#생성자 모델 => 길이가 100인 벡터를 받고 [64, 64, 1] 크기 텐서를 출력
generator = models.Model(generator_input, generator_output)
generator.summary()
Conv2DTranspose 층을 쌓을때 strides를 2로 지정해 텐서가 네트워크들을 통과하면서 공간 방향의 크기가 증가하게 된다.
반대로 채널 수는 줄어들게 됨 (마지막에는 흑백 이미지에 해당하는 1이 됨)

* 업샘플링과 전치합성곱
Conv2DTranspose 층 대신 UpSampling2D 층 + strides 1인 Conv2D층 을 사용할 수 있다.
x = layers.UpSampling2D(size = 2)(x)
x = layers.Conv2D(256, kernel_size = 4, strides = 1, padding = "same")(x)
업샘플링층은 단순히 입력 각각 행과 열을 반복해 크기를 두배로 늘림. 이후 Conv2D를 사용해 합성곱 연산을 수행.
-> 전치합성곱과 비슷하지만 픽셀 사이 공간을 0으로 채우지 않고 기존 픽셀 값을 사용한다는 차이점이 있음 (기본값은 가장 가까운 픽셀 값으로 채우는 nearest로 지정)
Conv2DTranspose는 출력 이미지 경계에 계단, 체크무늬 등 패턴을 만들어 품질을 떨어뜨린다는 단점이 있으나, 여전히 많이 사용하긴함.
업샘플링, 전치합성곱 모두 원본 이미지 차원으로 되돌리는데 사용할 수 있는 변환 방법이므로 사용자가 모두 모델 환경에서 모두 테스트해서 더 나은 것을 채택하면 된다.
이제 본격적으로 DCGAN 훈련을 진행해야한다.
훈련 데이터의 진짜 이미지와 생성자가 출력한 가짜 이미지를 합쳐 훈련 세트를 만들어 판별자 훈련을 진행한다
* 판별자 훈련 : 지도학습, 진짜 이미지 레이블 1, 가짜 이미지 레이블 0, 손실 함수 이진 크로스 엔트로피 사용
다음은 생성자 훈련으로 생성된 이미지에 점수를 부여하고 높은 점수를 낸 이미지로 최적화한다 (배치 이미지를 생성하고 판별자에 통과시켜 각 이미지에 대한 점수를 얻을 수 있음)
* 생성자 훈련 : 손실함수 이진 크로스 엔트로피
이때 한번에 한 네트워크의 가중치만 업데이트 되도록 번갈아 훈련해야함 (각 네트워크의 가중치를 다르게 변경해줘야하기 때문)
class DCGAN(models.Model):
def __init__(self, discriminator, generator, latent_dim):
super(DCGAN, self).__init__()
# 판별자, 생성자, 잠재공간 차원 설정
self.discriminator = discriminator
self.generator = generator
self.latent_dim = latent_dim
def compile(self, d_optimizer, g_optimizer):
super(DCGAN, self).compile()
self.loss_fn = losses.BinaryCrossentropy() #손실함수 이진 크로스 엔트로피
self.d_optimizer = d_optimizer #판별자 옵티마이저
self.g_optimizer = g_optimizer #생성자 옵티마이저
#훈련 중 추적할 메트릭 설정
self.d_loss_metric = metrics.Mean(name="d_loss") #판별자 손실
self.d_real_acc_metric = metrics.BinaryAccuracy(name="d_real_acc") #진짜 이미지에 대한 정확도
self.d_fake_acc_metric = metrics.BinaryAccuracy(name="d_fake_acc") #가짜 이미지에 대한 정확도
self.d_acc_metric = metrics.BinaryAccuracy(name="d_acc") #전체 정확도
self.g_loss_metric = metrics.Mean(name="g_loss") #생성자 손실
self.g_acc_metric = metrics.BinaryAccuracy(name="g_acc") #생성된 이미지에 대한 정확도
@property
def metrics(self):
return [
self.d_loss_metric,
self.d_real_acc_metric,
self.d_fake_acc_metric,
self.d_acc_metric,
self.g_loss_metric,
self.g_acc_metric,
]
def train_step(self, real_images):
# 잠재 공간(다변량 표준분포)에서 랜덤 포인트 샘플링
batch_size = tf.shape(real_images)[0]
random_latent_vectors = tf.random.normal(
shape=(batch_size, self.latent_dim)
)
# 가짜 이미지로 판별자 훈련하기
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = self.generator(
random_latent_vectors, training=True
) # 생성자에 전달, 이미지 배치 생성
#진짜 이미지에 대한 판별자 예측
real_predictions = self.discriminator(real_images, training=True)
#가짜 이미지에 대한 판별자 예측
fake_predictions = self.discriminator(
generated_images, training=True
)
real_labels = tf.ones_like(real_predictions)
real_noisy_labels = real_labels + NOISE_PARAM * tf.random.uniform(
tf.shape(real_predictions)
) #노이즈를 추가해 실제 레이블 생성
fake_labels = tf.zeros_like(fake_predictions)
fake_noisy_labels = fake_labels - NOISE_PARAM * tf.random.uniform(
tf.shape(fake_predictions)
) #노이즈를 추가해 가짜 레이블 생성
d_real_loss = self.loss_fn(real_noisy_labels, real_predictions)
d_fake_loss = self.loss_fn(fake_noisy_labels, fake_predictions)
# 판별자 손실 = 진짜이미지, 가짜이미지에 대한 이진 크로스 엔트로피 평균
d_loss = (d_real_loss + d_fake_loss) / 2.0
# 생성자 손실 = 진짜 이미지(레이블 1), 생성된 이미지에 대한 판별자 예측 사이의 이진 크로스 엔트로피
g_loss = self.loss_fn(real_labels, fake_predictions)
gradients_of_discriminator = disc_tape.gradient(
d_loss, self.discriminator.trainable_variables
)
gradients_of_generator = gen_tape.gradient(
g_loss, self.generator.trainable_variables
)
# 판별자와 생성자의 가중치 각각 업데이트 진행
self.d_optimizer.apply_gradients(
zip(gradients_of_discriminator, discriminator.trainable_variables)
)
self.g_optimizer.apply_gradients(
zip(gradients_of_generator, generator.trainable_variables)
)
# 메트릭 업데이트
self.d_loss_metric.update_state(d_loss)
self.d_real_acc_metric.update_state(real_labels, real_predictions)
self.d_fake_acc_metric.update_state(fake_labels, fake_predictions)
self.d_acc_metric.update_state(
[real_labels, fake_labels], [real_predictions, fake_predictions]
)
self.g_loss_metric.update_state(g_loss)
self.g_acc_metric.update_state(real_labels, fake_predictions)
return {m.name: m.result() for m in self.metrics}
(+ 레이블에 노이즈 추가하기, GAN 훈련 시 훈련 레이블에 랜덤 노이즈를 소량 추가하면 훈련 과정의 안정성이 개선되고 이미지를 선명하게 생성할 수 있음. 판별자가 풀어야되는 과제가 좀 더 어려워지므로 생성자를 과도하게 압도하지 못하게 됨. => 레이블 평활화 label smoohing)
다음으로 GAN을 컴파일 시키고 훈련 에포크마다 생성되는 이미지의 성능을 확인해본다.
#DCGAN 컴파일
dcgan.compile(
d_optimizer=optimizers.Adam(
learning_rate=LEARNING_RATE, beta_1=ADAM_BETA_1, beta_2=ADAM_BETA_2
),
g_optimizer=optimizers.Adam(
learning_rate=LEARNING_RATE, beta_1=ADAM_BETA_1, beta_2=ADAM_BETA_2
),
)class ImageGenerator(callbacks.Callback):
def __init__(self, num_img, latent_dim):
self.num_img = num_img
self.latent_dim = latent_dim
def on_epoch_end(self, epoch, logs=None):
if epoch % 10 == 0: # 출력 횟수를 줄이기 위해
random_latent_vectors = tf.random.normal(
shape=(self.num_img, self.latent_dim)
)
generated_images = self.model.generator(random_latent_vectors)
generated_images = generated_images * 127.5 + 127.5
generated_images = generated_images.numpy()
display(
generated_images,
save_to="./저장경로/이미지이름_%03d.png" % (epoch),
)dcgan.fit(
train,
epochs=EPOCHS,
callbacks=[
model_checkpoint_callback,
tensorboard_callback,
ImageGenerator(num_img=10, latent_dim=Z_DIM),
],
)




결과를 보면 생성자가 훈련 세트에서 추출한 것 같은 실제와 비슷한 이미지를 만드는데 점점 능숙해짐을 볼 수 있다.
마지막으로 새로운 이미지를 생성해본다.
우선, 잠재 공간에서 포인트를 샘플링하고 디코딩해 이미지를 생성한다.
# 표준 정규 분포에서 잠재 공간의 일부 포인트를 샘플링
grid_width, grid_height = (10, 3)
z_sample = np.random.normal(size=(grid_width * grid_height, Z_DIM))
# 샘플링된 포인트 디코딩
reconstructions = generator.predict(z_sample)
# 디코딩된 이미지 그리기
fig = plt.figure(figsize=(18, 5))
fig.subplots_adjust(hspace=0.4, wspace=0.4)
# 레고 이미지 그리드 출력
for i in range(grid_width * grid_height):
ax = fig.add_subplot(grid_height, grid_width, i + 1)
ax.axis("off")
ax.imshow(reconstructions[i, :, :], cmap="Greys")

다음으로 생성된 이미지와 훈련 세트에서 가장 유사한 이미지를 찾아 비교한다.
#생성된 이미지와 가장 유사한 이미지를 찾기 위한 함수 정의
def compare_images(img1, img2):
return np.mean(np.abs(img1 - img2))
#훈련 세트의 모든 이미지를 모으고 배열로 변환
all_data = []
for i in train.as_numpy_iterator():
all_data.extend(i)
all_data = np.array(all_data)
#생성된 이미지 출력
r, c = 3, 5
fig, axs = plt.subplots(r, c, figsize=(10, 6))
fig.suptitle("Generated images", fontsize=20)
noise = np.random.normal(size=(r * c, Z_DIM))
gen_imgs = generator.predict(noise)
cnt = 0
for i in range(r):
for j in range(c):
axs[i, j].imshow(gen_imgs[cnt], cmap="gray_r")
axs[i, j].axis("off")
cnt += 1
plt.show()
#훈련 세트에서 가장 유사한 이미지 출력
fig, axs = plt.subplots(r, c, figsize=(10, 6))
fig.suptitle("Closest images in the training set", fontsize=20)
cnt = 0
for i in range(r):
for j in range(c):
c_diff = 99999
c_img = None
for k_idx, k in enumerate(all_data):
diff = compare_images(gen_imgs[cnt], k)
if diff < c_diff:
c_img = np.copy(k)
c_diff = diff
axs[i, j].imshow(c_img, cmap="gray_r")
axs[i, j].axis("off")
cnt += 1
plt.show()
GAN 훈련 시 주의사항
1. 판별자 성능이 생성자보다 월등 (판별자 > 생성자)
판별자가 생성자보다 너무 강하면 손실 함수 신호가 미약해져 생성자에서 의미 있는 향상이 없어짐.
최악은 판별자가 진짜,가짜 이미지를 완벽히 학습하여 구분하게 되고 기울기가 완전히 사라져 학습이 전혀 이루어 지지 않게 되는 경우도 발생.
생성자가 향상되지 않으면 판별자를 약화하는 방법을 도입한다.
- 판별자 Dropout 층 rate 매개변숫값을 증가 => 네트워크 정보의 양을 줄임.
- 판별자 학습률을 줄임
- 판별자 합성곱 필터 수 줄임
- 판별자 훈련 시 레이블에 잡음 추가
- 판별자 훈련 시 일부 이미지 레이블 무작위 배치
2. 생성자 성능이 판별자보다 월등 (생성자 > 판별자)
생성자가 판별자보다 너무 강하면 거의 동일한 몇 개의 이미지로 판별자를 쉽게 속이는 방법이 학습된다 => "모드 붕괴"
판별자를 항상 속이는 하나의 샘플이미지(모드)를 찾으려는 경향이 생기고 잠재 공간 모든 포인트를 여기에 매핑하게 된다. 손실 함수의 기울기가 0에 가까운 값으로 붕괴하게 되므로 이 상태에서 벗어날 수 없게됨을 뜻한다.
즉 생성자는 하나만 만들거나 극히 일부만 만들게 되는 것.
3. 유용하지 않은 손실
GAN 훈련과정을 모니터링 하기 어렵게 만드는 문제.
일반적으로 딥러닝 모델은 손실 함수를 최소화하므로 생성자 손실이 작을수록 이미지 품질이 좋을것이라 생각하게 되는데 생성자는 판별자에 의해 평가되고 판별자는 계속 향상되므로 훈련 과정 중 다른 지점에서 평가된 손실을 비교할 수가 없다.
실제로 에포크 그래프를 통해 비교해보면 계속 이미지 품질이 향상되는데도 생성자의 손실 함수는 증가하는 경우도 볼 수 있다.
4. 하이퍼파라미터
GAN은 간단한 모델이더라도 튜닝해야하는 하이퍼파라미터 개수가 많다.
판별자, 생성자 구조와 배치 정규화, 드롭아웃, 학습률, 활성화 층, 합성곱 필터, 커널 크기, 스트라이드, 배치크기, 잠재 공간 크기 등을 고려한다.
GAN은 파라미터 변화에 민감하므로 여러 계획적인 시행착오를 거쳐 맞는 파라미터 조합을 찾아야한다. (GAN 내부 작동원리를 이해하고 손실함수를 해석해야하는 이유라고 볼 수 있음ㅠ)
여기까지 GAN , DCGAN에 대한 내용을 공부했다
다음 게시글로는 이미지 생성 과정 안정성, 품질 개선을 위한 와서스테인 GAN-그레이디언트 패널티 (WGAN-GP)를 공부해보고자한다!
'스터디 > AI' 카테고리의 다른 글
| [이론/Imple] 자기회귀 모델 (autogressive model) (1) | 2024.05.19 |
|---|---|
| [이론/Imple] 생성적 적대 신경망 (GAN) 2 (2) | 2024.05.14 |
| [이론/Imple] Variational autoencoder, VAE 변이형 오토인코더 2 (0) | 2024.04.30 |
| [이론/Imple] Variational autoencoder, VAE 변이형 오토인코더 1 (1) | 2024.04.28 |
| [Imple] 캐릭터 분류를 위한 컴퓨터비전 신경망 예제 심화 이미지 특성 추출사용 (1) | 2023.05.25 |