[이론/Imple] 자기회귀 모델 (autogressive model)
이 게시물은 <만들면서 배우는 생성 AI 2판> 교재의 내용과 소스코드를 기반으로 실습한 내용을 기반으로 하고있다.
https://github.com/rickiepark/Generative_Deep_Learning_2nd_Edition/
GitHub - rickiepark/Generative_Deep_Learning_2nd_Edition: <만들면서 배우는 생성 AI 2판>의 코드 저장소
<만들면서 배우는 생성 AI 2판>의 코드 저장소. Contribute to rickiepark/Generative_Deep_Learning_2nd_Edition development by creating an account on GitHub.
github.com
LSTM 네트워크
LSTM은 순환신경망(recurrent neural network, RNN) 의 종류로 Long Short-Term Memory의 약자이다.
일반적인 RNN은 장기 의존성 문제(long-term dependencies)로 인해 긴 시퀀스 데이터에서 잘 작동하지않는 문제가 있었다. 이를 해결하기 위해 고안된 네트워크 방식이 LSTM이다.
LSTM은 이전 정보를 오랫동안 기억할 수 있도록 게이트 메커니즘(gate mechanism)을 사용해 정보의 흐름을 제어하고, 기존 RNN에 비해 더 긴 기간 동안 정보를 기억할 수 있도록 한다.
LSTM 실습은 텍스트 데이터를 사용하는데 먼저 텍스트 데이터에 대해 살펴본다.
텍스트 데이터는 이미지 데이터와 몇몇 차이점이 있다.
1. 이미지 데이터는 연속적인 색상 스펙트럼 위 데이터고, 텍스트 데이터는 개별적인 데이터 (문자, 단어)로 구성된다.
=> 이미지 데이터에는 역전파를 쉽게 적용할 수 있으나 이산적인 텍스트 데이터는 일반적인 방식으로 역전파를 적용할 수 없다.
2. 이미지 데이터는 두 개의 공간 차원이 있으나 시간 차원은 없다. 텍스트 데이터는 시간 차원은 있으나 공간차원은 없다.
=> 텍스트 데이터에서 단어의 순서는 매우 중요, 순서에 대한 의존성이 있는 경우가 많음
3. 텍스트 데이터는 개별 단위 (문자, 단어)의 작은 변화에도 매우 민감하다.
4. 이미지 데이터는 픽셀 값 할당을 위한 사전 정의된 규칙이 없으나, 텍스트 데이터는 규칙 기반 문법 구조가 있다.
다음은 케글에 있는 레시피 데이터를 사용한 LSTM 네트워크 실습코드이다.
https://www.kaggle.com/datasets/hugodarwood/epirecipes
Epicurious - Recipes with Rating and Nutrition
Recipes from Epicurious by rating, nutritional content, and categories
www.kaggle.com
먼저 사용할 라이브러리를 import 한다.
import numpy as np
import json
import re
import string
import tensorflow as tf
from tensorflow.keras import layers, models, callbacks, losses
네트워크에 사용할 파라미터를 정의한다.
VOCAB_SIZE = 10000
MAX_LEN = 200
EMBEDDING_DIM = 100
N_UNITS = 128
VALIDATION_SPLIT = 0.2
SEED = 42
LOAD_MODEL = False
BATCH_SIZE = 32
EPOCHS = 25
사용할 데이터를 로드하고 제목, 설명이 있는 레시피만 남도록 필터링을 진행한다.
# 전체 데이터셋 로드
with open("./데이터 경로/full_format_recipes.json") as json_data:
recipe_data = json.load(json_data)
# 데이터셋 필터링
filtered_data = [
"Recipe for " + x["title"] + " | " + " ".join(x["directions"])
for x in recipe_data
if "title" in x
and x["title"] is not None
and "directions" in x
and x["directions"] is not None
]
# 예제 데이터 출력
example = filtered_data[9]
print(example)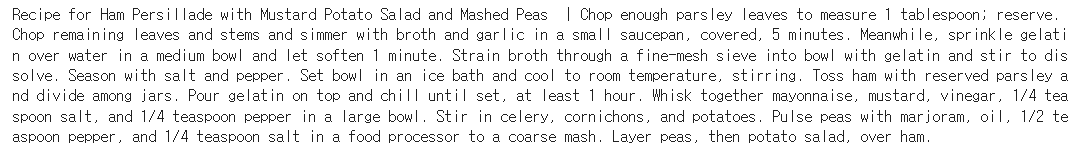
본격적으로 텍스트 데이터를 LSTM 신경망으로 훈련하는 단계를 진행한다.
먼저 첫번째로 데이터를 정제하고 토큰화를 진행한다. (토큰화는 텍스트를 단어, 문자 같은 개별 단위로 나누는 작업을 의미)
1. 단어 토큰 처리
- 고유명사를 제외하고는 모든 텍스트를 소문자로 변환한다.
- 어휘사전이 매우 클 수 있다.
- 희소한 단어는 unknown word로 처리하는게 신경망 가중치 수를 줄일 수 있음.
- 단어에서 어간을 추출
- 구두점은 토큰화하거나 모두 제거
2. 문자 토큰 처리
- 단어 토큰화에 비해 어휘사전이 비교적 적음
- 마지막 출력층에 학습할 가중치 수가 적기 때문에 모델의 훈련 속도에 유리.
실습에서는 어간 추출 없이 소문자 다어로 토큰화를 진행한다 (문장의 끝, 인용 부호 시작과 끝 예측을 위해 구두점도 토큰화 진행)
#구두점이 단어와 분리된 별도 토큰으로 취급될 수 있도록 하는 함수
def pad_punctuation(s):
# 모든 구두점을 앞뒤로 공백을 추가하여 분리
s = re.sub(f"([{string.punctuation}])", r" \1 ", s)
# 다중 공백을 단일 공백으로 변환
s = re.sub(" +", " ", s)
return s
# filtered_data의 모든 텍스트 데이터에 대해 구두점을 분리
text_data = [pad_punctuation(x) for x in filtered_data]
# 텐서플로 데이터셋으로 변환
text_ds = (
tf.data.Dataset.from_tensor_slices(text_data) # 텍스트 데이터를 텐서플로 데이터셋으로 변환
.batch(BATCH_SIZE) # 배치 크기만큼 데이터 묶기
.shuffle(1000) # 데이터셋 셔플
)
# 벡터화 층 만들기
vectorize_layer = layers.TextVectorization(
standardize="lower", # 모든 텍스트 소문자로 변환
max_tokens=VOCAB_SIZE, # 어휘 사전의 최대 크기 지정
output_mode="int", # 텍스트를 정수 시퀀스로 변환
output_sequence_length=MAX_LEN + 1, # 출력 시퀀스의 최대 길이를 설정
)
# 훈련 세트에 층 적용
vectorize_layer.adapt(text_ds) # TextVectorization 층을 훈련 데이터에 적용
vocab = vectorize_layer.get_vocabulary() # vocab 변수에 단어 토큰 리스트 저장
토큰화를 진행한 후 인덱스에 매핑된 토큰 리스트의 일부를 확인한다.
# 토큰:단어 매핑 샘플 일부 출력
for i, word in enumerate(vocab[:10]):
print(f"{i}: {word}")
0 토큰은 중지토큰에 할당, 1 토큰은 상위 10,000개 단어를 벗어난 알 수 없는 언노운 단어에 할당한다.
다른 단어는 빈도순으로 토큰이 할당된다.
다음으로 데이터셋을 생성한다.
# 레시피와 한 단어 이동한 동일 텍스트로 훈련 세트를 만듭니다.
def prepare_inputs(text):
text = tf.expand_dims(text, -1)
tokenized_sentences = vectorize_layer(text)
x = tokenized_sentences[:, :-1]
y = tokenized_sentences[:, 1:]
return x, y
train_ds = text_ds.map(prepare_inputs)
#입력과 동일하지만 한 토큰 이동된 벡터로 구성된 훈련세트를 만듦
다음으로 LSTM 모델 구조를 만든다.
inputs = layers.Input(shape=(None,), dtype="int32")
x = layers.Embedding(VOCAB_SIZE, EMBEDDING_DIM)(inputs)
x = layers.LSTM(N_UNITS, return_sequences=True)(x)
outputs = layers.Dense(VOCAB_SIZE, activation="softmax")(x)
lstm = models.Model(inputs, outputs)
lstm.summary()
# 손실 함수 = SparseCategoricalCrossentropy
loss_fn = losses.SparseCategoricalCrossentropy()
# Adam 옵티마이저 적용
lstm.compile("adam", loss_fn)

모델 층에서 Embedding 층은 각 정수 토큰을 embedding_size 길이의 벡터로 변환하는 lookup table 이다.
룩업 벡터는 모델에 의해 학습되는 가중치로 임베딩층에서 학습되는 가중치 개수는 어휘 사전 크기에 임베딩 벡터 차원을 곱한 값이다.
(어휘 사전 크기 10,000 , 임베딩 크기 100 => 10,000 * 100 = 1,000,000 )
Input 층이 [batch_size, seq_length] 크기의 정수 시퀀스 텐서를 Embedding 층으로 전달하면 이 층은
[batch_size, seq_length, embedding_size] 크기 텐서를 출력한다.
이때 출력된 텐서가 LSTM 층으로 전달된다.
다음은 제작한 LSTM을 분석하는 실습코드를 작성한다.
=> 기존 단어 시퀀스를 네트워크에 주입, 다음단어 예측
=> 이 단어를 기존 시퀀스에 추가하고 과정 반복
# TextGenerator 콜백 클래스 정의 (학습 후 텍스트를 생성하기 위함)
class TextGenerator(callbacks.Callback):
def __init__(self, index_to_word, top_k=10):
# 인덱스를 단어로 변환하는 딕셔너리와 단어를 인덱스로 변환하는 딕셔너리 초기화
self.index_to_word = index_to_word
# 어휘 사전 역매핑 (단어 -> 토큰)
self.word_to_index = {
word: index for index, word in enumerate(index_to_word)
}
# temperature 매개변수를 사용해 확률을 업데이트
def sample_from(self, probs, temperature): #temperature가 0에 가까울수록 샘플링이 더 결정적
# 확률 분포에 온도를 적용하여 샘플링
probs = probs ** (1 / temperature)
probs = probs / np.sum(probs)
# 확률 분포에 따라 다음 단어를 샘플링
return np.random.choice(len(probs), p=probs), probs
def generate(self, start_prompt, max_tokens, temperature):
# 시작 프롬프트를 토큰으로 변환 (시작 프롬프트 : 생성 과정을 시작하기 위해 모델에 제공하는 단어의 문자열)
start_tokens = [
self.word_to_index.get(x, 1) for x in start_prompt.split()
]
sample_token = None
info = []
# 최대 토큰 수에 도달하거나 샘플 토큰이 0일 때까지 반복
while len(start_tokens) < max_tokens and sample_token != 0:
# 현재 토큰 시퀀스를 모델에 입력하여 다음 단어 예측
x = np.array([start_tokens])
y = self.model.predict(x, verbose=0)
# 예측 결과에서 샘플링
sample_token, probs = self.sample_from(y[0][-1], temperature)
# 생성된 단어와 확률 정보 저장
info.append({"prompt": start_prompt, "word_probs": probs})
# 샘플링된 토큰을 시작 토큰에 추가
start_tokens.append(sample_token)
start_prompt = start_prompt + " " + self.index_to_word[sample_token]
# 최종 생성된 텍스트 출력
print(f"\n생성된 텍스트:\n{start_prompt}\n")
return info
def on_epoch_end(self, epoch, logs=None):
# 각 에포크가 끝날 때마다 텍스트 생성
self.generate("recipe for", max_tokens=100, temperature=1.0)
# 시작 프롬프트 토큰화
text_generator = TextGenerator(vocab)
# 모델 학습 시작 (학습 데이터셋, 에포크 수, 콜백 리스트 포함)
lstm.fit(
train_ds,
epochs=EPOCHS,
callbacks=[model_checkpoint_callback, tensorboard_callback, text_generator],
)
'temperature' 매개변수는 텍스트 생성 모델에서 샘플의 무작위성을 조절하는 역할을 한다.
확률 분포를 조정해 모델이 단어를 선택할 때의 다양성을 조절한다.
'temperature'가 낮을수록 모델을 더 확실하고 예측 가능한 단어를 선택하며, 'temperature'가 높을수록 모델은 더 다양하고 창의적인 단어를 선택하게 된다.
마지막으로 LSTM을 통해 실제로 텍스트를 생성해본다.
# 단어 확률을 출력하는 함수 정의
def print_probs(info, vocab, top_k=5):
for i in info:
print(f"\n프롬프트: {i['prompt']}")
word_probs = i["word_probs"]
# 상위 top_k 개의 확률을 내림차순으로 정렬
p_sorted = np.sort(word_probs)[::-1][:top_k]
# 상위 top_k 개의 인덱스를 내림차순으로 정렬
i_sorted = np.argsort(word_probs)[::-1][:top_k]
for p, i in zip(p_sorted, i_sorted):
print(f"{vocab[i]}: \t{np.round(100*p,2)}%")
print("--------\n")# "recipe for roasted vegetables | chop 1 /" 프롬프트로 최대 10개의 토큰을 생성하고, 온도는 1.0
info = text_generator.generate(
"recipe for roasted vegetables | chop 1 /", max_tokens=10, temperature=1.0
)
# 생성된 토큰들의 확률을 출력
print_probs(info, vocab)
# 동일한 프롬프트로 최대 10개의 토큰을 생성하지만, 온도는 0.2
info = text_generator.generate(
"recipe for roasted vegetables | chop 1 /", max_tokens=10, temperature=0.2
)
# 생성된 토큰들의 확률을 출력
print_probs(info, vocab)

info = text_generator.generate(
"recipe for chocolate ice cream |", max_tokens=7, temperature=1.0
)
print_probs(info, vocab)
info = text_generator.generate(
"recipe for chocolate ice cream |", max_tokens=7, temperature=0.2
)
print_probs(info, vocab)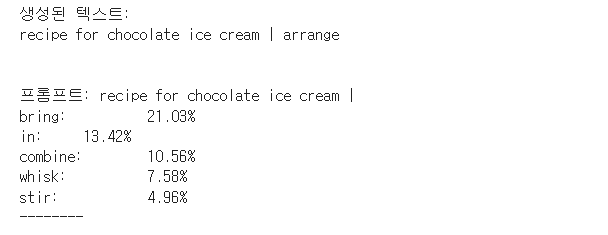

생성 결과를 보면
temperature=1.0 으로 생성된 텍스트가 temperature=0.2로 생성된 텍스트보다 더 모험적이고 정확도가 떨어짐을 알 수 있다.
일반적으로 temperature가 낮을 때 생성 결과에 다양성이 적은 이유로, temperature=0.2로 생성된 샘플의 확률을 보면 첫 번째 선택 토큰에 훨씬 더 많은 가중치가 부여됨을 볼 수 있다.
여기까지 LSTM 기반 텍스트 생성모델 실습을 진행하였다.
자기회귀 모델로 LSTM을 활용해 텍스트 데이터를 학습, 생성하는 방법은 여러 장점이 있으나 단점과 한계점도 크게 존재한다.
1. 구조적 한계 : LSTM은 매우 긴 시퀀스를 학습하는데 한계가 있고, 문맥이 긴 텍스트에 대해 정보 손실이 발생할 수 있다
2. 데이터 처리 한계 : 충분히 다양한 데이터가 없으면 편향된 출력이 될 수 있고, LSTM에 맞게 텍스트 데이터를 전처리 하는 과정이 복잡하다.
3. Tansformer 모델 대체 : Transformer 모델(GPT, BERT)이 LSTM을 대체하는 경우가 많아졌다, 트랜스포머 모델은 병렬처리에 적합하고 긴 시퀀스에도 더 나은 성능을 보이는 경우가 많다.